比特浏览器新闻数据采集方法
作为一名跨境电商运营人员,同时也涉足内容采集工作,我深刻体会到高质量新闻数据采集对市场决策的重要性。近期我发现,比特浏览器(官网:bitbrowser.cn)凭借其强大的指纹防护和多账号管理功能,成为新闻数据采集的利器。接下来,我将结合个人真实操作体验,分享比特浏览器下新闻数据采集的具体方法和实用技巧。
一、为什么选择比特浏览器进行新闻数据采集?
在新闻数据采集过程中,最大挑战是:频繁访问会被目标网站封禁IP或者账号,尤其是多账号并行操作时更容易被检测关联封号。比特浏览器基于谷歌Chromium内核深度开发,拥有以下优势:
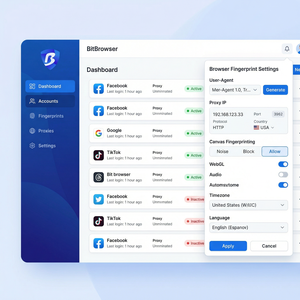
- 多环境独立运行:可同时开启多个浏览器环境窗口,每个窗口模拟独立的设备指纹信息(如UA、分辨率、时区、WebGL、Canvas等),实现账号间完全隔离,避免账号关联。
- 灵活代理IP配置:支持多种代理协议,能够为每个环境单独设置代理IP,保障采集数据源IP多样化,降低封禁风险。
- 自动化RPA操作:内置RPA自动化功能,能定时自动刷新页面、滚动加载、点击等操作,提高采集效率。
- 云端同步和群控:支持团队多账号统一管理,操作同步,提升新闻采集的团队协作效率。
二、比特浏览器新闻数据采集的具体操作步骤
1. 下载和安装比特浏览器
访问比特浏览器官网(bitbrowser.cn),选择适合系统的安装包,下载安装完成后打开浏览器。免费版已提供10个独立环境窗口,基本满足中小规模采集需求。
2. 创建多个独立环境窗口
- 点击主界面左上角“新建环境”按钮,创建一个独立浏览环境。
- 进入环境设置,针对该环境调整指纹参数,如用户代理(UA)、语言、分辨率、时区等,模拟真实用户设备差异。
- 为该环境绑定专属代理IP,建议使用稳定的高匿名代理,保证IP独立且经常更换。
- 重复以上步骤,根据需要创建多个环境,实现多账号账号并行运行。
3. 采集新闻数据的自动化设置
利用比特浏览器内置的RPA自动化工具:
- 设置自动刷新或定时访问指定新闻网站。
- 编写简单的点击、滚动脚本,模拟人工操作,激活更多新闻内容加载。
- 结合自定义插件管理,支持导出HTML或JSON格式的数据,方便后续分析。
4. 防关联封号的注意事项
- 确保每个浏览环境的指纹信息差异明显。
- 定期更换代理IP,避免长时间使用同一IP。
- 避免批量频繁大流量访问同一新闻网站,使用自动化脚本时加适当延时。
- 开启比特浏览器权限管理,避免员工误操作导致数据泄露。
三、实用技巧分享
利用云端同步功能统一管理多环境
我个人非常推荐使用比特浏览器的云端同步功能,能够将多台电脑或者不同团队成员的采集环境同步,保证数据统一和操作一致,大大提高新闻采集的效率和规范性。
合理利用API接口调用实现数据精准采集
比特浏览器官网提供了丰富的API接口,支持自动调用浏览器环境执行脚本,适合批量采集新闻数据的技术用户。配合后台数据处理,可实现新闻采集流程的全自动闭环。
扩展插件管理增强功能
比特浏览器允许加载自定义Chrome插件,我个人借助某些网页数据采集插件,实现了更加灵活和精细的新闻内容抓取,比如自动下载PDF新闻报道、解析JS渲染的新闻列表等。
四、常见问题解答
Q1:免费版环境窗口够用吗?
免费版提供10个环境窗口,适合小规模采集。如果需要同时管理更多账号或更高级的自动化功能,可以考虑付费版。
Q2:如何保证代理IP的安全和稳定?
建议使用正规代理服务商的高匿名代理,并定期更换代理,避免被封禁和IP污染。
Q3:如何避免新闻网站识别机器人采集?
通过比特浏览器强大的指纹防护和模拟真实用户行为(如滚动、点击),有效降低被识别风险。同时可以适当调整访问频率,做到“人性化”采集。
总结
通过上述步骤和技巧,利用比特浏览器官网提供的多环境独立、多指纹防护、代理配置及自动化功能,能够实现高效、安全的新闻数据采集,极大提升跨境电商和内容运营的工作效率。作为一名重度用户,我强烈推荐大家下载体验比特浏览器,结合自身需求灵活应用,保证数据采集稳定且账号安全。
如果你也需要多账号运营和防关联浏览的专业支持,欢迎访问比特浏览器官网,开始你的高效数据采集之旅!